
Sommaire
Stable Diffusion est un outil qui vous permet de générer des images et des photos aléatoires. Il fonctionne avec une IA (intelligence artificielle) au même titre que le célèbre chatGPT qui a révolutionné ce domaine depuis plusieurs mois maintenant. Avant chatGPT, il y a eu DALL-E 2 puis Midjourney, qui sont les premiers programmes d’intelligence artificielle connus qui consistent à créer des images à partir de descriptions textuelles appelées aussi « Prompts ».
Midjourney vous laisse gratuitement générer jusqu’à 25 images et s’utilise avec le programme Discord. Dépassé ce quota, vous devrez prendre un abonnement démarrant à 10 dollars pour 200 crédits. Stable Diffusion est lui, un logiciel open source, totalement gratuit et sans restrictions.
Je vous mets ici quelques exemple que j’ai effectué pour avoir un avant de goût des possibilités qui s’offrent à vous 🙂




Stable Diffusion
Stable diffusion à plusieurs versions dont la série 1.x avec la 1.4 et la 1.5, qui est la plus utilisée et les nouvelles versions 2.x avec la 2.0 et la 2.1. Cette dernière corrige plusieurs problèmes rencontrés de la 2.0, qui ont à l’époque, fait rebasculer les utilisateurs vers la version 1.5.
Je vous propose d’essayer les deux versions en ligne les plus populaires :
Essayez la version Stable Diffusion 1.5
Essayez la version Stable Diffusion 2.1
Cette application est installée sur un serveur qui ne nécessite pas d’inscription et qui est totalement gratuit. Si vous préférez opter pour la version locale, assurez d’avoir un bon ordinateur possédant une bonne carte graphique. Cependant, la version locale offre beaucoup plus de possibilités que celle en ligne, à vous de voir suivant vos besoins.
Installer Stable Diffusion
Stable Diffusion a été créé par Automatic1111. Vous pouvez installer son interface graphique en local sur plusieurs types de plateformes dont Windows, Mac et Linux.
Prévoyez de l’espace sur le disque dur entre 3go et 8go suivant la version du modèle de Stable Installation que vous voulez mettre en place. L’installation reste assez simple, nous allons voir comment procéder.
Stable Diffusion Mac Os
Avant de procéder à son installation sur Mac, voici quelques notes postées par le créateur :
Actuellement, la plupart des fonctionnalités de l’interface utilisateur Web fonctionnent correctement sur macOS, les exceptions les plus notables étant l’interrogateur CLIP et la formation. Bien que l’entraînement semble fonctionner, il est incroyablement lent et consomme une quantité excessive de mémoire. L’interrogateur CLIP peut être utilisé mais il ne fonctionne pas correctement avec l’accélération GPU utilisée par macOS, de sorte que la configuration par défaut l’exécutera entièrement via le processeur (ce qui est lent).
- Dans un premier temps, il faut installer Homebrew
- Ouvrez un terminal et taper la commande suivante pour installer tous les paquets nécessaires
brew install cmake protobuf rust python@3.10 git wget
- Installer l’interface graphique Stable Diffusion
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
- Téléchargez un modèle de Stable Diffusion et placez le, dans le répertoire
stable-diffusion-webui/models/Stable-diffusion. Les fichiers ont une extension de type .ckpt

- Maintenant que le modèle est mise en place et que vous avez installé Stable diffusion, nous allons nous mettre dans le repertoire du programme
cd stable-diffusion-webui- Nous allons ensuite vérifier si une mise à jour n’est pas disponible
git pull
- Nous pouvons désormais lancer l’application Stable Diffusion qui installera quelques derniers paquets
./webui.sh
- A la fin du lancement, ne fermez surtout pas votre terminal pendant l’utilisation du logiciel. C’est à travers lui que votre programme Stable Diffusion va fonctionner. Sur la ligne « Running on local URL: » vous avez un serveur local de lancé. Il vous suffira juste d’ouvrir votre navigateur et de reporter cette adresse dans l’url à saisir.

L’interface graphique de Stable Diffusion ressemblera à ceci
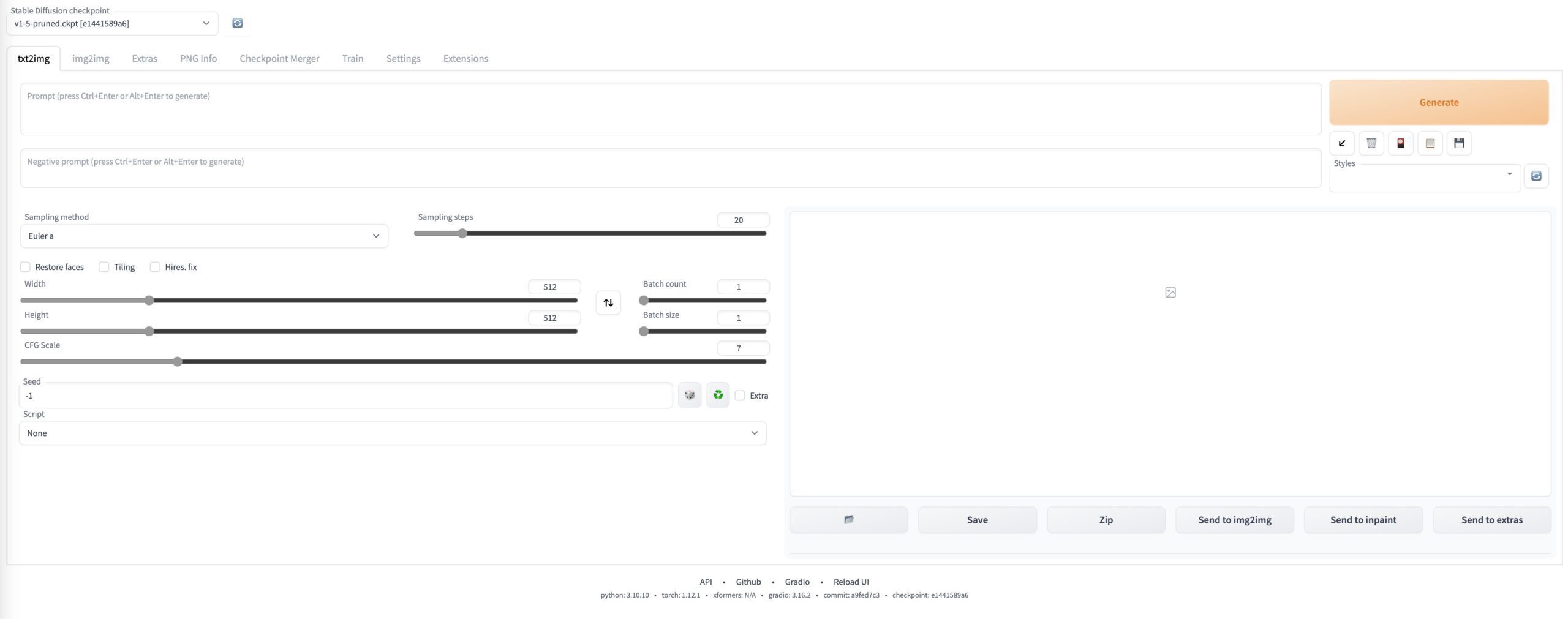
Stable Diffusion Windows pour les éditions avant Windows 10
- Il faut tout d’abord télécharger et installer Python 3.10.6 et le programme Git.
- Ouvrez ensuite le terminal windows et lancez la commande suivante
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui- Allez ensuite dans le répertoire créé : exemple C:\bureau\stable-diffusion-webui
- Téléchargez un ou plusieurs modèles de Stable Diffusion et placez les, dans le répertoire
stable-diffusion-webui/models/Stable-diffusion. Les fichiers ont une extension de type .ckpt - Double cliquez sur le fichier webui-user.bat pour lancer le programme
- Comme sur mac, vous allez avoir une url à la ligne « Running on local URL: » reportez là dans votre navigateur web et laissez ouvert le terminal pour que l’application puisse fonctionner.
Stable Diffusion Windows 10 et 11
- Allez télécharger l’installeur rapide sur le gitub ou en lien direct A1111 Webui Launcher V1.7.0.
- Lancez le programme d’installation A1111.Web.UI.Autoinstaller.v1.7.0.exe et choisissez le chemin où l’installer. Cochez la case « Clean install » s’il s’agit de votre première installation via ce programme d’installation automatique. Décochez-la si vous souhaitez uniquement mettre à jour le lanceur et conserver votre interface Web existante intacte (avec vos paramètres/modèles/extensions, etc.). Cliquez ensuite sur le bouton « Install ».

- Une fois installé, un dossier s’ouvrira avec un raccourci appelé A1111 WebUI.
- Lancez le raccourci pour ouvrir le programme.
- Il devrait installer toutes les dépendances et vous demander si vous souhaitez télécharger le modèle SD de base pour générer des images
⚠️ Cliquez sur « Non » uniquement si vous avez déjà un ou plusieurs modèles quelque part, et si c’est le cas, n’oubliez pas de sélectionner leurs dossiers parents dans le lanceur. - Une fois que vous avez configuré le lanceur selon vos préférences, cliquez sur « Launch Webui, cela quittera le lanceur et poursuivra dans la fenêtre du terminal, en enregistrant ce qu’il fait.
⚠️ Soyez patient, cela prendra un certain temps au début, quand il sera prêt, il ouvrira l’interface Web dans votre navigateur.
⚠️ Lisez le message d’AVERTISSEMENT. - Lorsque vous avez terminé d’utiliser l’interface Web, fermez l’onglet du navigateur et fermez la fenêtre du terminal.
- Double-cliquez sur A1111 WebUI vous devriez être accueilli avec le lanceur.

Browse : Cela va parcourir le dossier stable-diffusion-webui.
Reset : Cela effacera le dossier stable-diffusion-webui et le reclonera depuis github ⚠️ Le dossier est définitivement supprimé donc faites des sauvegardes si besoin ! Une pop up vous demandera confirmation.
Auto-Update WebUI : Cela mettra à jour (git pull) la WebUI chaque fois que vous la lancerez.
Auto-Update Extensions : Même chose mais avec les extensions.
Effacer les images générées : Cela effacera toutes les images générées précédemment du dossier de sortie au lancement. ⚠️ Les images sont définitivement supprimées ! Une pop up vous demandera confirmation.
Les boutons « Force » à côté des fonctions ci-dessus exécuteront la fonction correspondante dès que vous cliquerez au lieu d’attendre le lancement.
Remarque : Si vous avez un dossier de sortie personnalisé, seul le dossier spécifié dans le champ « Output directory for images; if empty, defaults to three directories below » dans les paramètres de l’interface Web sera effacé.
Low VRAM : Permet aux cartes avec une faible VRAM de pouvoir générer des images, cela augmentera le temps de rendu, mais rendra les choses fluides.
Xformers : Accélère considérablement les cartes RTX 3000/4000, peut parfois aussi fonctionner avec les anciennes cartes Gens !
Checkpoint folder : Si vous n’avez pas de dossier de point de contrôle spécifique, ne cliquez pas dessus, sinon sélectionnez-le ici💡cliquez sur le chemin pour réinitialiser.
Default VAO: Cela vous permettra de sélectionner un fichier VAE par défaut dis
Stable Diffusion Linux
- Télécharger Python et Git
sudo apt install wget git python3 python3-venv- Installer l’interface graphique Stable Diffusion
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui- Rendez-vous dans le répertoire d’installation
cd stable-diffusion-webui- Téléchargez un ou plusieurs modèles de Stable Diffusion et placez les, dans le répertoire
stable-diffusion-webui/models/Stable-diffusion. Les fichiers ont une extension de type .ckpt - Vérifiez sur une mise à jour n’est pas proposée
git pull- Lancez l’application qui installera dans un même temps torch et torchvision
./webui.sh
- Comme sur mac, vous allez avoir une url à la ligne « Running on local URL: » reportez là dans votre navigateur web et laissez ouvert le terminal pour que l’application puisse fonctionner.
L’option txt2image de Stable Diffusion
Cette option, qui est l’onglet par défaut, vous donne la possibilité de rentrer dans le champs « prompt », des mots clés permettant la création d’image.
En dessous de cette case prompt, vous retrouvez « Negative prompt ». Dedans vous devez inscrire, tous les mots clés qui vont éviter de parasiter votre demande de prompt.

Exemple :
Case prompt : femme, blonde, robe noir, vêtements très détaillés, ambiance chic, château, 8k
Case negative prompt : visage sombre, hors cadre, déformé, infirme, laid, bras supplémentaires, jambes supplémentaires, tête supplémentaire, deux têtes, plusieurs personnes, groupe de personnes
Il faut jouer avec plusieurs paramètres pour obtenir ce que l’on recherche. Dans ceux-ci vous avez :
- Stable Diffusion checkpoint : Qui est la sélection du fichier modèle (se trouvant tout en haut à gauche) qui servira à réaliser la modélisation.
- Sampling method : Il s’agit de la méthode utilisée pour confectionner la photo, vous avez tout un tas de choix.
- Sampling steps : Combien de fois le logiciel va améliorer l’image générée; des valeurs plus élevées prennent plus de temps alors que des valeurs très faibles peuvent produire de mauvais résultats.
- Width et Height : La largeur et la hauteur de l’image
- CFG Scale: permet de communiquer au logiciel, dans quelle mesure l’image doit être conforme au prompt.
- Batch count : Le nombre d’images à créer (n’a aucun impact sur les performances de génération ou l’utilisation de la VRAM).
- Batch size : Le nombre d’images créé en un seul lot (augmente les performances de génération au prix d’une utilisation plus élevée de la VRAM)
- Seed : C’est une valeur généré par le logiciel une fois que la création est réalisée. En laissant la valeur par défaut -1, il génère des images aléatoires. En entrant une valeur, sa base de calcul va se référer à cette valeur là.
- Script : Lancer un script pré-enregistré pour notamment créer des tests sur les prompts.
Vous avez aussi une case nommée « extra » qui déploie encore d’autres options.. eh oui c’est personnalisable sur beaucoup de points :
- Variation seed : pour mixer plusieurs valeurs de valeurs seed.
- Variation strength : Quelle est la force d’une variation à produire. A 0, il n’y aura aucun effet. À 1, vous obtiendrez l’image complèter avec une variation de seed.
- Resize seed from width et Resize seed from heigh : Faire une tentative pour reproduire une image similaire à ce qui aurait été produit avec le même seed avec une autre résolution spécifiée (longueur, largeur).
Bon et une fois que l’on a réglé tout cela et que l’on a généré notre image, les paramètres que vous avez choisis sont réécris en dessous de la photo. Par exemple, je travaille dans la confection d’habits déguisés pour enfants et j’aimerai rechercher une jeune fille avec une belle robe de princesse pour me donner des idées.
Voila ma configuration :
beautiful child girl, portrait, very finely detailed princess dress, intricate design, golden, pink, cinematic lighting, 4k
Negative prompt: easynegative
Negative prompt: easynegative
Steps: 50, Sampler: LMS, CFG scale: 8, Seed: 508124122, Size: 512x512, Model hash: 02e37aad9f, Model: openjourney-v4
Time taken: 51.93sNous allons maintenant garder cette même configuration, en laissant bien dans le champs « seed », la valeur 508124122. Essayons via le script X/Y/Z plot et en indiquant dans le champs X type : seed, de varier ce seed par les valeurs 5, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100. Cette méthode donne la possibilité de varier le résultat donné pour s’axer par la suite sur le seed qui nous correspond le mieux.

Dans cette galerie, j’ai trouvé par exemple que le seed 80 correspondait plus à mes attentes. Je vais donc changer mon seed qui était de 508124122 et je lui rajoute la valeur de 80 ce qui donnerait le nouveau seed à 508124202.
On va maintenant tenter de faire varier l’option CFG Scale par ces mêmes valeurs même si ici, elles n’ont pas de relation : 5, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100

Suite au rendu, je souhaite maintenant repartir sur le CFG scale 5. Je vais donc reporter le 5 dans ma case de base. Dans l’étape suivante, je vais faire la même chose que les deux précédentes fois mais je vais changer le script sur steps et je vais mettre sur les variations 10, 20, 30, 40, 50, 60, 70, 80, 90, 100 sachant que 5 n’est pas une valeur possible pour le steps. D’ailleurs si vous voyez un problème en lançant une option et que rien ne se passe, regardez les messages d’erreurs éventuels dans le terminal. Exemple : RuntimeError: Unknown sampler: 5.

On voit de légères différences entre les trois premières photos, avec la première qui n’a pas les bras croisés et la troisième qui a son voile légèrement différent. On va donc choisir un autre choix de script X/Y/Z plot mais avec pour l’axe des X = « Sampler » (qui correspond à Sampling method) avec les valeurs Euler a, Heun, LMS, DPM++ 2S a, DDIM, PLMS et sur l’axe des Y = Steps avec les valeurs 10, 20, 30, 40, 50, 60, 70, 80, 90, 100. Ce résultat va donc générer plusieurs steps avec plusieurs méthodes, ce qui donnera une bonne visibilité sur les possibilités.

Avec ce test, on a une bonne vision globale des changements entre ces deux paramétrages. On peut en conclure que pour la plupart des « Sampling method », pousser les steps à plus de 50, ca n’apporte que peut d’intérêts. De plus, plus on pousse le nombre de steps, puis la génération est longue ! Après avoir faits de nombreux tests avec différentes photos, ce n’est pas toujours le cas mais globalement c’est assez similaire.



L’option img2img de Stable Diffusion
Cet outil est regorgé d’options pour tout customiser manuellement. En plus de générer automatiquement une image d’après ce que vous inscris dans le prompt, il est aussi possible d’utiliser une image source de départ pour ensuite en créer une nouvelle.
Vous retrouvez cette option dans la version locale de Stable Diffusion, dans l’onglet img2img.
Par rapport à notre premier onglet txt2image, img2img rajoute 1 option supplémentaire :
- Denoising strength : Détermine le respect que l’algorithme doit avoir par rapport au le contenu de l’image. À 0, rien ne changera, et à 1, vous obtiendrez une image sans rapport.
Mon but dans cet exemple est de partir sur une femme avec un look de pocahontas et la transformer par la suite. Nous allons donc utiliser le numéro « Seed » donné par l’application lors de la première génération de photo faite dans le premier onglet. D’ailleurs, vous pouvez directement importe l’image générée dans la première partie en cliquant sur le bouton « Send to img2img ». Je vous communique ce que j’ai inscris pour obtenir l’image suivante :
mdjrny-v4 style portrait photograph of Madison Beer as Pocahontas, young beautiful native american woman, perfect symmetrical face, feather jewelry, traditional handmade dress, armed female hunter warrior, (((wild west))) environment, Utah landscape, ultra realistic, concept art, elegant, ((intricate)), ((highly detailed)), depth of field, ((professionally color graded)), 8k, art by artgerm and greg rutkowski and alphonse mucha
Negative prompt: (((backlight))), dark face, white fur, gold fabric, ((cropped head)), ((out of frame)), deformed, cripple, ugly, additional arms, additional legs, additional head, two heads, multiple people, group of people
Steps: 100, Sampler: Euler a, CFG scale: 7, Seed: 203920787, Size: 512x512, Model hash: 02e37aad9f, Model: openjourney-v4
Time taken: 1m 59.62s
Avant cela, testons l’option Denoising Strength en utilisant toujours le même script, avec les mêmes options de pocahontas notées ci-dessus. Dans le champs X, j’ai sélectionné Denoising et j’ai inséré les valeurs suivantes : 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1

Si on ne change pas le prompt, les changements ne sont pas flagrants. On va donc le modifier en créant sur la même base (en gardant le seed de la femme pocahontas), un chien pocahontas ! Toutefois, je laisse le champs du Negative prompt, sur le même paramètre que cette dernière. Voici ce que j’ai configuré dans le prompt :
chien, peluche, decors neutre
Negative prompt: (((backlight))), dark face, white fur, gold fabric, ((cropped head)), ((out of frame)), deformed, cripple, ugly, additional arms, additional legs, additional head, two heads, multiple people, group of people
Steps: 100, Sampler: LMS, CFG scale: 7, Seed: 203920787, Size: 512x512, Model hash: 02e37aad9f, Model: openjourney-v4, Denoising strength: 0.1, Mask blur: 4
Time taken: 9m 54.81s
Ici, le résultat est satisfaisant entre le Denoising 0.5 et le 0.7. Je pourrai donc pousser le vice en allant chercher plus de mesures entre ces deux valeurs
On aime les tests, on part désormais sur le même script avec en X = Denoising avec une valeur de 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1 et un axe Y = CGF Scale d’une valeur de 5, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100
Nous allons avoir une implémentation simultanée de ces deux caractéristiques.

Dans ce résultat, on est parti vraiment cherché le détail, peu de photos sont réellement exploitables. J’en ai retenu seulement sept.
Exemple suivant, il serait intéressant d’utiliser ces deux mêmes paramètres de script mais dans le sens inverse simultané. Ça donnerait X = Denoising avec une valeur de 0.6, 0.62, 0.65, 0.68, 0.7 et un axe Y = CGF Scale d’une valeur de 10, 15, 20, 25, 30

Dernier exemple on va maintenant faire le contraire X = Denoising avec une valeur de 1, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1 et un axe Y = CGF Scale d’une valeur de 100, 90, 80, 70, 60, 50, 40, 30, 20, 10



Affinez vos résultats au fur et à mesure jusqu’à obtenir le résultat parfait 🙂
Vous avez tout un tas d’autres possibilités, via les autres onglets, à vous de les explorer. Le but étant pour moi, de vous donner un premier aperçu de ce qu’il est possible de réaliser.
Petit bonus ! Le dénommé JHawkk a réalisé une option supplémentaire nommée LoRA, qui permet d’obtenir des résultats vraiment impressionnant. Téléchargez LoRA puis mettez ce fichier openjourneyLora.safetensors dans le dossier : stable-diffusion-webui/models/lora et utilisez en cliquant sur la deuxième option extra ici :

Et allez dans cet onglet :

Je vous mets juste en dessous, 2 photos obtenues avec notre amie LoRA :
full body cyborg| full-length portrait| detailed face| symmetric| steampunk| cyberpunk| cyborg| intricate detailed| to scale| hyperrealistic| cinematic lighting| digital art| concept art| mdjrny-v4 style
Negative prompt: bad anatomy| blurry| fuzzy| disfigured| misshaped| mutant| deformed| bad art| out of frame
Steps: 30, Sampler: Euler a, CFG scale: 8, Seed: 2877208998, Size: 512x512, Model hash: 02e37aad9f, Model: openjourney-v4
Time taken: 2m 14.46s
full body cyborg| full-length portrait| detailed face| symmetric| steampunk| cyberpunk| cyborg| intricate detailed| to scale| hyperrealistic| cinematic lighting| digital art| concept art| mdjrny-v4 style
Negative prompt: bad anatomy| blurry| fuzzy| disfigured| misshaped| mutant| deformed| bad art| out of frame
Steps: 30, Sampler: Euler a, CFG scale: 8, Seed: 2877208998, Size: 512x512, Model hash: 02e37aad9f, Model: openjourney-v4
Time taken: 2m 14.46s
Openjourney : la version de Stable Diffusion, concurrent de Midjourney
Openjourney s’utilise avec Stable Diffusion. C’est plus ou moins une version détournée pour générer des images avec le style de Midjourney.
Vous pouvez l’utiliser de deux manières : en local (par une installation sur votre machine) ou en ligne.
Openjourney la version de l’outil en ligne
Une version en ligne d’Openjourney est disponible pour le grand public, ne nécessitant pas d’installation. Vous pouvez vous amuser directement à générer des images en tapant ce que vous souhaitez dans la ligne « Prompt ». Plus vous allez fournir de détails dans la description, plus vous aurez un résultat satisfaisant.
Si vous souhaitez vous baser sur la style de l’outil Midjourney, il vous faudra insérer dans la ligne prompt, le code suivant au début de votre recherche : mdjrny-v4 style. Il est possible d’obtenir plusieurs tailles d’images sans dépassé le 1024×768 ou le 768×1024, le cas échant cela provoquera une erreur.
Une petite chose à savoir concernant la génération de photos. Même si vous ne changez pas la phrase du prompt, le résultat obtenu sera différent à chaque fois. Vous avez donc la possibilité de demander plusieurs fois la même demande jusqu’à obtenir un résultat satisfaisant. L’option « num_outputs » laisse le choix entre 1 ou 4 photos générées à la fois.

Une fois que vous avez réglé tous les paramètres, cliquez tout en bas sur le bouton « Submit ». Sur la gauche, plusieurs barres de progression se rempliront jusqu’à obtenir votre photo. Par la suite, il est possible de la partager via le bouton « Share » ou tout simplement de la sauvegarder avec le bouton « Download ».
Openjourney la version locale à installer
Openjourney a aussi sa version installable qui fonctionne avec Stable Diffusion. Installez dans un premier temps Stable Diffusion puis placez le fichier OpenJourney V4 dans le répertoire stable-diffusion-webui/models/Stable-diffusion comme ceux vus précédemment dans le tutoriel d’installation.
Choisissez ensuite quelle version vous souhaitez utiliser via le sélecteur en haut à gauche de Stable Diffusion.

Comment composer un prompt ?
Le but du prompt est de donner un maximum de détails pour obtenir quelque chose de satisfaisant. Vous pouvez utiliser le Français mais il y a de bien meilleurs résultat en Anglais (vous pouvez utiliser un traducteur si besoin). Sur le site de prompthero.com une galerie d’exemples vous est proposée ainsi qu’un moteur de recherche. Vous avez plus bas, au dessus des photos, des pré-filtres suivant le logiciel que vous utilisez.

Une fois qu’un modèle vous inspire, cliquez dessus et vous aurez le détail du prompt écrit par l’utilisateur pour obtenir son résultat.

Sur le côté droit, vous avez en gras, le prompt indiqué et en dessous de celui-ci, la taille de l’image, les paramètres « Seed », « guidance_scale », « num_inference_steps » utilisés. Reportez toutes ces indications dans le logiciel et contemplez le résultat.

Suivant les images, vous pouvez avoir parfois deux paramètres « Prompts » à rentrer. C’est le cas pour l’exemple ci-dessus. Il vous faudra alors utiliser la version de Stable Diffusion en local (à installer sur votre ordinateur) pour débloquer l’option « Negative prompt ».
Quel est le mieux entre Stable Diffusion et Midjourney ?
C’est difficile d’avoir une vraie réponse. Tout dépend de vos goûts personnels. Niveau qualité d’image, c’est un très proche. Bien que les deux programmes soient capables de produire des résultats bluffants, MidJourney AI semble un peu plus poussé en matière de détails artistiques.
Par contre Stable Diffusion donne globalement des photos beaucoup plus naturelles que celles de MidJourney.

